Angular.js Guide for Seasoned Developers – part 1
This is a high-level overview of Angular.js (or 1st version of Angular), targeted to experienced JavaScript developers, after which you’ll understand the concepts. It is not a replacement for angular guides and api reference, and it explans only main concepts – my goal was to explain how Angular.js works so that you’ll know what to expect from this framework. I assume you worked with Angular for a little bit, or at least skimmed over their docs.
Angular.js is a pretty old framework (first commit at January 3rd 2010), and a lot of guides contain obsolete information, and many target beginners (which totally makes sense, since it was the coolest kid on the block). Also, nowadays nobody really talks about Angular.js (which is an official name for the first version), and I wanted to fill this gap, brief introduction with all concepts explaining, for experienced developers, with short examples and links to learn more.
While these links are helpful, though, I highly recommend to read the guide thoroughly first, and only after start to deep dive into the links (but feel free to use just links, if it suits you better!).
TOC
My experience
I’ve never worked with Angular in production before. I’ve heard terrible rumours (1, 2, etc), I’ve applied to certain jobs where it was a requirement, and I’ve played with it on my own (lack of links here tells for my success with it). At some point I’ve even learnt about digest cycle (we will learn about it soon!), but still had no idea how to actually write angular.js application. After some point Angular2 (nowadays 5) was released, and after that I just gave up on it.
But ironically on my new job we use Angular.js. Well, it is partially tweaked to workaround some issues, and it is officially admitted that it is a dead end, so we are migrating into glorious React land, but for now a big chunk of the application is written using Angular 1.5. After working about half an year on it, I have to say that it is not that bad actually – I’d say the biggest problem lies in allowing (and sometimes even encouraging) bad practices – scope inheritance, I look at you!
My experience was: jQuery -> Backbone -> Knockout -> React (with couple of custom frameworks around these tools in native JS). I am pretty experienced by frontend measure, about 5 years, and I decided to write this short guide how Angular.js works targeting people with similar path – a lot of experience in JS and frontend, but not a lot of with Angular.
Basics
Angular was built with extension of regular HTML in mind, so the simplest angular application is just a regular HTML page, but with a new weird ng-* attributes inside. The main directive ng-app, which is usually added on the <html> or <body> tags, tells Angular that it need to parse all markup inside and apply its rules. Angular parses everything, trying to find specific tags, attributes, classes or even comments (last two are usually frowned upon by community). After it encounters one, it does something depending on the type:
- if it is a custom tag, when it looks for registered directives (we will discuss them in details later), which can be used as tags, inserts its template and repeats the process – parses it, looking for other special markers
- if it is a custom attribute and it is a user-defined directives which applies to tags, this custom behaviour is added
- if it is a custom attribute with a built-in directive, then different behaviour is added. I won’t cover all of them, and right now let’s discuss only one –
ng-controller.
This is a simple example, but it goes beyond what we learned so far – `` inside our markup. Now, let’s look at controllers in more details.
See the Pen ZxdyPO by Seva Zaikov (@bloomca) on CodePen.
Controllers
Originally, controllers were the only way to add certain behaviour to HTML (I might be wrong here, as in any part of this article), so there are a lot of them, especially in legacy parts. New functionality usually is written using directives (which we’ll cover soon!), because they allow to break functionality into more encapsulated components, but under the hood new controller is created each time anyway (same thing for some built-in directives).
Every time we use ng-controller attribute, Angular searches for the declared controller (via dependency injection, we’ll touch it briefly), and creates a new instance using new keyword. Following the best traditions, there are two ways to use it – you can just set name of the controller, which you registered using Angular’s dependency injection (more on it later), or you use controllerAs syntax. In case you use the latter, you can just treat controller as a construction function, which will be invoked with a new keyword, and all properties on this will be available inside template. controllerAs syntax makes it clearer from which controller we want to get properties, so I personally like it more, but it is more about convention.
After we create instance, all variables declared on it (or on $scope, depending whether you declared using controllerAs syntax or not) are available in this scope. Scope is a magical angular thing, which gives you access to everything declared on it inside your HTML template. Controllers by default have parent scopes in their prototype chain, so it means that you can change properties in absolutely unpredictable places, and this is a really big problem (it is a widely recognized problem, just be super careful).
Just to recap: every time we create a new nested controller, it has a parent scope as a prototype, so you can accidentally change value of some parent controller
Also, remember that everything is inside some scope, and some built-in directives create a new one, and there is a common problem with declaring ng-model directive, which adds two-way data-binding from your scope to the input, when you change property in the child scope, which was introduced by another directive, but you actually wanted to change it inside your own, now parent directive!
I am pretty sure it sounds a little bit confusing, so please read much better and in-depth explanation of this issue: StackOverflow question with good answers.
As I mentioned before several times, each scope puts previous one in a prototypal chain. In practice it means that inside your HTML code each time you nest ng-controller attributes, they create a new scope, but have everything from parent scopes in prototype chain. It adds a lot of confusion, because it becomes unclear from where exactly value comes from (or where it was changed later), so in Angular 1.3 was introduced a special syntax controllerAs, which forces you to prefix all values with the name of controller. Better to illustrate:
See the Pen ControllerAs syntax Angular.js by Seva Zaikov (@bloomca) on CodePen.
As you can see, there is no disambiguity, and we are 100% sure which scope is referred in each specific case. Nowadays directives (or components, which are just wrappers around directives) are preferred, but old code still uses controllers extensively.
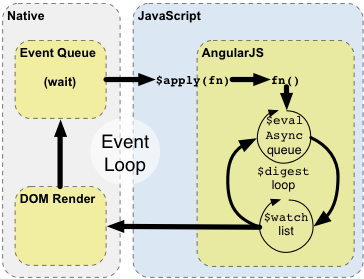
How Watching Works (or Digesting Cycle)
This is the most magical part of Angular, and also the biggest source of bugs, performance issues and all that hatred which Angular has (maybe after scope inheritance). Angular.js has two-way data binding by default – you don’t really need to do anything to make it work, you just update values on scope and it should reflect in HTML automatically; this is how Angular itself became so popular. There are some quirks here, but the most important thing here is that by default magic works only if you do everything using angular directives/services, so they will cause HTML to re-render.
In the basics I’ve described how angular parses templates, but did not go into details. So, let’s write super simple counter example and see how does it work:
See the Pen angular.js event example by Seva Zaikov (@bloomca) on CodePen.
We added some interactivity here – namely, number of clicks, and the ability to reset it. Initial render will show us expected 0, but what will happen next? ng-click allows us to add click handlers, and as any other expression in angular, the value is evaluated using eval, so we have to write code like it will be executed inside click handler. If we click on this button, magically in our html we will see that number increased by 1. How does it work?
When angular sets up your controller in ng-controller or custom directive, after instantiating controller it will also set up all needed listeners. But how does it know that something has changed? In fact, it does not. Angular has its own digesting cycle, which shows the whole execution model of the framework. So, watchers just react to changes after special signal, called $scope.$digest() or $scope.$apply() (don’t worry too much about difference between them – you can read this SO answer now or later about it) – you can invoke it manually, actually, and sometimes you have to! You have to do so if angular has no idea what are you doing, and usually it means you don’t use any angular directive/service at all.
For example, if we have a controller, which defines a variable, and then change it after some timeout, nothing will happen:
See the Pen angular.js no $digest example by Seva Zaikov (@bloomca) on CodePen.
So, previous example does not work, which makes us puzzled – where is the magical two-way data binding? As I said, you have to force $scope to start digesting cycle, after which it will realize that value now has another value, and it re-render HTML. So, working controller from the previous example will look like this:
lt-tab=”js,result” data-user=”bloomca” data-embed-version=”2” data-pen-title=”angular.js with $digest example” class=”codepen”>See the Pen angular.js with $digest example by Seva Zaikov (@bloomca) on CodePen.</p>
The problem is that now we have to write these updates manually all the time – for Promises, for network requests, for timeouts, for global DOM events, for literally everything asynchronous! This is the reason why Angular provides a lot of services by default, which basically mimic existing functionality, but it wraps them in a function, which automatically invokes $scope.$digest() under the hood, so you don’t have to do it all the time. Another good point is that it becomes extremely easy to mock everything, because we everything is custom.
For timeouts we have $timeout service, which does exactly that – it will execute your function, and then apply digesting automatically.
See the Pen angular.js with $timeout example by Seva Zaikov (@bloomca) on CodePen.
So, keep in mind that if you don’t use built-in angular services, or you have some bridge which consumes outside events, you will need to trigger these changes by yourself. Also, in case you have a lot of updates in ~10 ms (depends on browser) timeframe – it might be beneficial to use $scope.$applyAsync(), which will update in batches; but as in any performance-related topic, please test it first, and don’t do premature optimizations.
Conclusion
This was only the first part – we did not cover directives, services and factories, along with dependency injection mechanism, which we’ll for sure do next time. Some material I won’t even discuss, but it is totally okay – Angular.js has really big API surface, so only concepts really matter. I hope it was useful and you can understand some things better! See you next time.