Node.js Guide for Frontend Developers
This guide is focused on frontend developers – people who know JavaScript, but are not very proficient with Node yet. I won’t focus on the language here – Node.js uses V8, so it is the same interpreter as in Google Chrome, which you probably know about (however, it is possible to run on different VMs, see node-chakracore).
Table of Contents
- Node Version
- No Babel is Needed
- Callback Style
- Event Loop
- Event Emitters
- Streams
- Module System
- Environment Variables
- Putting Everything Together
- Conclusion
We deal with Node.js pretty often nowadays, even if you are a frontend developer – npm scripts, webpack configuration, gulp tasks, programmatic run of bundlers or test runners. Even though you don’t really need deep understanding for these sort of tasks, it might be confusing sometimes, and cause you to write something in a very weird way just because of missing some key concepts of Node.js. Familiarity with Node can also allow you to automate some things you do manually, feeling more confident looking into server-side code and writing more complicated scripts.
Node Version
The most shocking difference after client-side code is the fact that you decide on your runtime, and you can be absolutely sure about supported features – you choose which version you are going to use, depending on your requirements and available servers.
Node.js has a public release schedule, which tells us that odd versions don’t have long-term support, and that the current LTS (long-term support) version will be actively developed until April 2019, and then maintained with critical updates until December 31, 2019. New versions of Node are being actively developed, and they bring a lot of new features, along with security updates and performance improvements, which might be a good reason to use the current active version. However, nobody really forces you, and if you don’t want to do that, there is nothing wrong to use an older version, and to avoid updates until it is a good moment for you.
Node.js is used extensively in modern frontend toolchain – it is hard to imagine a modern project which does not include any processing using node tools, so you might be already familiar with nvm (node version manager), which allows you to have several node versions installed at the same time, choosing the correct version for each project. The reason for such a tool is that different projects very often are written using different Node versions, and you don’t want to constantly keep them in sync, you just want to preserve the environment in which they were written and tested. Such tools exist for many other languages, like virtualenv for Python, rbenv for Ruby and so on.
No Babel is Needed
Because you are free to choose any Node.js version, there is a big chance that you can use the LTS (Long term supported) version, which is 8.11.3 at the moment of writing, which supports almost everything – all ECMAScript 2015 spec, except for tail recursion.
It means that there is no need for Babel, unless you are stuck with a very old version of Node.js, need JSX transformation, or can’t live without some bleeding edge transformations. In practice, it is not that crucial, so your running code is the same as you have written it, without any transpiling – a gift we already forgot on the client-side.
There is also no need for webpack or browserify, and therefore we don’t have a tool to reload our code – in case you develop something like a web server, you can use nodemon to reload your application after filechanges.
And because we don’t ship this code anywhere, there is no need to minify it – one step less: you just use your code as is! It feels really weird.
Callback Style
Historically, asynchronous functions in Node.js accepted callbacks with a signature (err, data), where the first argument represented an error – if it was null, all is good, otherwise you have to handle the error.
These handlers are called after action was done and we had a response. For example, let’s read a file:
1
2
3
4
5
6
7
8
9
10
11
12
const fs = require('fs');
fs.readFile('myFile.js', (err, file) => {
if (err) {
console.error('There was an error reading file :(');
// process is a global object in Node
// https://nodejs.org/api/process.html#process_process_exit_code
process.exit(1);
}
// do something with file content
});
It was discovered soon that this style makes it extremely hard to write readable and maintainable code, and even created the notion callback hell. Later, new asynchronous primitive was introduced, Promise – it was standardized at ECMAScript 2015 (it is a global object both for browser and Node.js runtime). Recently, in ECMAScript 2017 async/await was standartized, and it became available in Node.js 7.6+, so you can use it in the LTS version.
With promises we avoid “callback hell”, but now we get the problem that old code, and a lot of built-in modules still use this technique. However, it is not very hard to convert them to promises – to illustrate, let’s convert fs.readFile to promises:
1
2
3
4
5
6
7
8
9
10
11
12
13
const fs = require('fs');
function readFile(...arguments) {
return new Promise((resolve, reject) => {
fs.readFile(...arguments, (err, data) => {
if (err) {
reject(err);
} else {
resolve(data);
}
});
});
}
This pattern can be easily extended to any function, and there is a special function in built-in utils module – utils.promisify. Example from the official documentation:
1
2
3
4
5
6
7
8
9
const util = require('util');
const fs = require('fs');
const stat = util.promisify(fs.stat);
stat('.').then((stats) => {
// Do something with `stats`
}).catch((error) => {
// Handle the error.
});
The Node.js core team understands that we need to move from the old style, so they are trying to introduce a promisified version of the built-in modules – there is promisified file system module already, although it is experimental at the moment of writing.
You can still encounter a lot of old-school Node.js code with callbacks, and it is recommended to wrap them using utils.promisify for the sake of consistency.
Event Loop
Event loop is almost the same as in the browser, with some extensions. However, since this topic is a little bit more advanced, I will cover it fully, not only the differences (I will highlight them though, so you know which part is Node.js-specific).
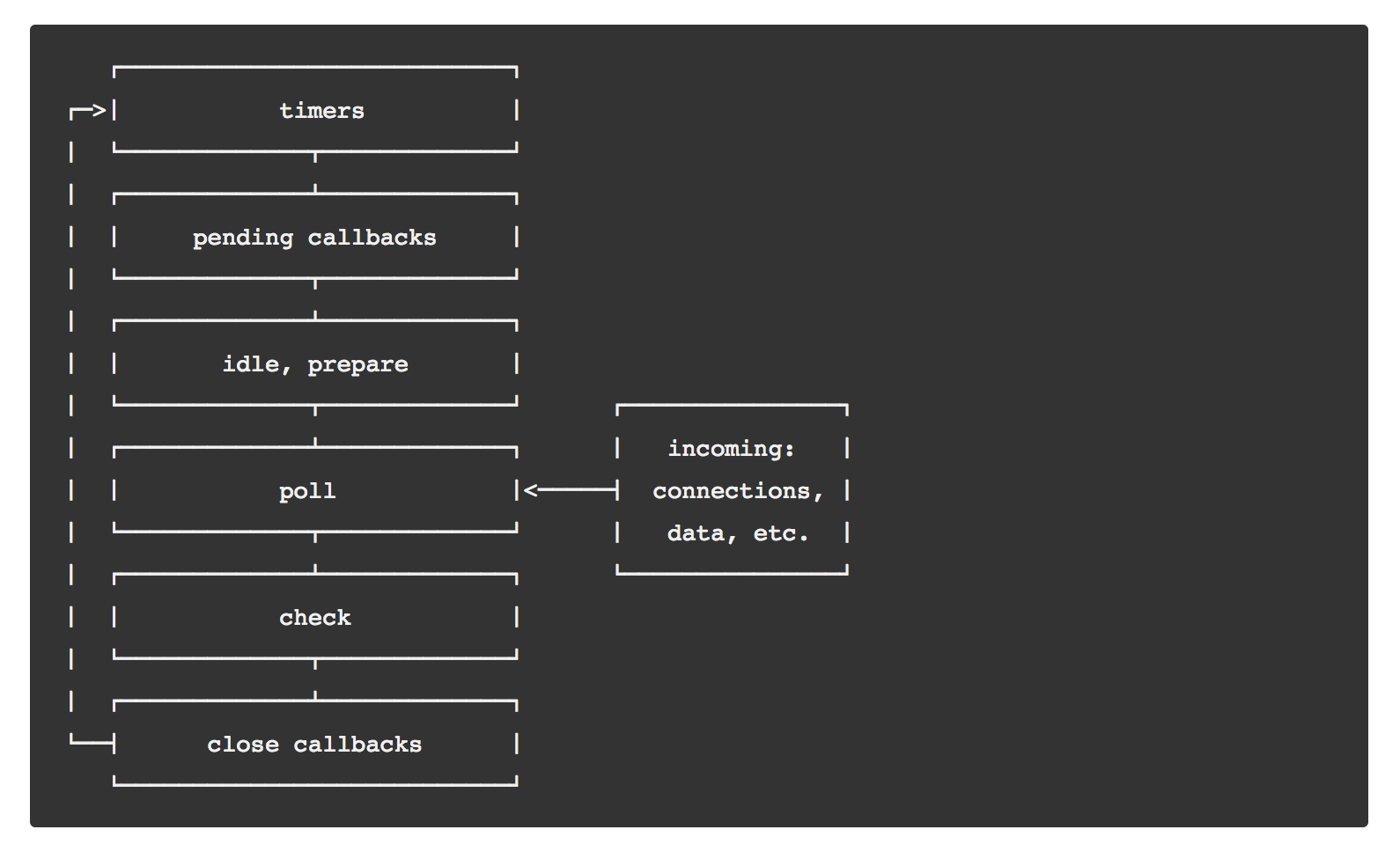 Event loop in Node.js
Event loop in Node.js
JavaScript is built with asynchronous behaviour in mind, and therefore very often we don’t execute everything right there. Here is a list with things which can be executed not in direct order:
For example, immediately resolved promises, like Promise.resolve. It means that this code will be executed in the same event loop iteration, but after all synchronous code.
This is a Node.js specific thing, it does not exist in any browser (as well as the process object). It behaves like a microtask, but with a priority, which means that it will be executed right after all synchronous code, even if other microtasks were introduced before – this is dangerous, and can lead to endless loops. The naming is unfortunate, since it is executed during the same event loop iteration, not on the next tick of it, but because of compatibility reasons it probably will remain the same.
While it does exist in some browsers, it did not reach consistent behaviour across all of them, so you should be very careful using it in the browser. It is similar to the setTimeout(0) code, but sometimes will take precedence over it. The naming here is also not the best – we are talking about next event loop iteration, and it is not really immediate.
Timers behave the same way both in Node and browser. One important thing about timers is that a delay which we provide is not a guaranteed time after which our callback will be executed. What it really means is that Node.js will execute this callback after this time as soon as the main execution cycle finished all operations (including microtasks) and there are no other timers with higher priority.
Let’s take a look at the example with all the above mentioned things:
I’ll put a correct output from the script’s execution further down, but if you want to, try to go through it by yourself (be a “JavaScript interpreter”):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
const fs = require('fs');
console.log('beginning of the program');
const promise = new Promise(resolve => {
// function, passed to the Promise constructor
// is executed synchronously!
console.log('I am in the promise function!');
resolve('resolved message');
});
promise.then(() => {
console.log('I am in the first resolved promise');
}).then(() => {
console.log('I am in the second resolved promise');
});
process.nextTick(() => {
console.log('I am in the process next tick now');
});
fs.readFile('index.html', () => {
console.log('==================');
setTimeout(() => {
console.log('I am in the callback from setTimeout with 0ms delay');
}, 0);
setImmediate(() => {
console.log('I am from setImmediate callback');
});
});
setTimeout(() => {
console.log('I am in the callback from setTimeout with 0ms delay');
}, 0);
setImmediate(() => {
console.log('I am from setImmediate callback');
});
The correct execution order is the following:
1
2
3
4
5
6
7
8
9
10
11
> node event-loop.js
beginning of the program
I am in the promise function!
I am in the process next tick now
I am in the first resolved promise
I am in the second resolved promise
I am in the callback from setTimeout with 0ms delay
I am from setImmediate callback
==================
I am from setImmediate callback
I am in the callback from setTimeout with 0ms delay
You can read more about event loop and process.nextTick in the official Node.js docs.
Event Emitters
A lot of core modules in Node.js emit or receive different events. Node.js has an implementation of EventEmitter, which is a publish-subscribe pattern. This is very similar to browser DOM events with a slightly different syntax, and the easiest thing we can do to understand it is to actually implement it on our own:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
class EventEmitter {
constructor() {
this.events = {};
}
checkExistence(event) {
if (!this.events[event]) {
this.events[event] = [];
}
}
once(event, cb) {
this.checkExistence(event);
const cbWithRemove = (...args) => {
cb(...args);
this.off(event, cbWithRemove);
};
this.events[event].push(cbWithRemove);
}
on(event, cb) {
this.checkExistence(event);
this.events[event].push(cb);
}
off(event, cb) {
this.checkExistence(event);
this.events[event] = this.events[event].filter(
registeredCallback => registeredCallback !== cb
);
}
emit(event, ...args) {
this.checkExistence(event);
this.events[event].forEach(cb => cb(...args));
}
}
This implementation just shows the pattern itself and does not target exact functionality – please don’t use it in your code!
This is all the basic code we need! It allows you to subscribe to events, unsubscribe later, and emit different events. For example, response object, request object, stream – they all actually extend or implement EventEmitter!
Because it is such a simple concept, it is implemented in a lot of npm packages: 1, 2, 3, and many others – so, if you want to use the same event emitter in the browser, feel free to use them.
Streams
“Streams are Node's best and most misunderstood idea.”
Dominic Tarr
Streams allow you to process data in chunks, not just as a result of the full operation (like reading a file). To understand why we do need them, let me show you a simple example: let’s say we want to return to a user a requested file of arbitrary size. Our code might look like this:
1
2
3
4
5
6
7
8
9
10
11
function (req, res) {
const filename = req.url.slice(1);
fs.readFile(filename, (err, data) => {
if (err) {
res.statusCode = 500;
res.end('Something went wrong');
} else {
res.end(data);
}
});
}
This code will work, especially on our local dev machine, but it might fail – do you see the issue?
We can have problems here in case the file is too big – when we read the file, we put everything into memory, and if we don’t have enough resources, this won’t work. This also won’t work in case we have a lot of concurrent requests – we have to keep data object in our memory until we have sent everything.
However, we don’t really need this file at all – we just return it from the file system, and we don’t look inside the content by ourselves, so we can read some part of it, return it immediately, free our memory, and repeat the whole thing again until we are done. This is a description of streams in a nutshell – we have a mechanism to receive data in chunks, and we decide what to do with this data. For example, we can do exactly the same:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
let result = '';
filestream.on('data', chunk => {
result += chunk;
});
filestream.on('end', () => {
res.end(result);
});
// if file does not exist, error callback will be called
filestream.on('error', () => {
res.statusCode = 500;
res.end('Something went wrong');
});
}
Here we create a stream to read from the file – this stream implements the EventEmitter class, and on a data event we receive the next chunk, and on an end event, we get a signal that the stream ended and then full file was read. This implementation works the same as before – we wait for the whole file to be read, and then return it in the response. Also, it has the same problem: we keep the whole file in our memory before sending it back. We can solve this problem if we know that the response object implements a writable stream itself, and we can write information into that stream without keeping it in our memory:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
filestream.on('data', chunk => {
res.write(chunk);
});
filestream.on('end', () => {
res.end();
});
// if file does not exist, error callback will be called
filestream.on('error', () => {
res.statusCode = 500;
res.end('Something went wrong');
});
}
Response object implements a writable stream, and fs.createReadStream creates a readable stream, and there are also duplex and transform streams. The difference between them and how they work exactly, is out of the scope of this tutorial, but it is good to know of their existence.
Now we don’t need the result variable anymore, we just write alredy read chunks into the response immediately, and we don’t keep it in our memory! It means that we can read even big files, and we don’t have to worry about a lot of parallel requests – since we don’t keep files in our memory, we won’t run out of it.
However, there is one problem. In our solution, we read from one stream (filesystem reading from a file) and write it into another (network request), and these two things have different latencies. By different I mean really different, and after some time our response stream will be overwhelmed, since it is much slower. This problem is a description of backpressure, and Node has a solution for it: each readable stream has a pipe method, which redirects all data into the given stream respecting its load: if it is busy, it will pause the original stream, and resume it. Using this method, we can simplify our code to:
1
2
3
4
5
6
7
8
9
10
11
12
function (req, res) {
const filename = req.url.slice(1);
const filestream = fs.createReadStream(filename, { encoding: 'utf-8' });
filestream.pipe(res);
// if file does not exist, error callback will be called
filestream.on('error', () => {
res.statusCode = 500;
res.end('Something went wrong');
});
}
Streams changed several times during Node’s history, so be extra careful while reading old manuals, and always check with the official documentation!
Module System
Node.js uses commonjs modules. You’ve probably already used them – every time you use require to get some module inside your webpack configuration, you actually use commonjs modules; every time you declare module.exports you use it as well. However, you might also have seen something like exports.some = {}, without module, and in this section we’ll see exactly how it works.
First of all, I’ll talk about commonjs modules, with regular .js extensions, not about .esm/.mjs files (ECMAScript modules), which allow you to use the import/export syntax. Also, what is important to understand, is that webpack and browserify (and other bundling tools) use their own require function, so please don’t be confused – we won’t touch them here, just be aware that it is slightly different (even though it behaves in a very similar fashion).
So, where do we actually get these “global” objects like module, require and exports? Actually, Node.js runtime adds them – instead of just executing the given javascript file, it actually wraps it in the function with all these variables:
1
2
3
function (exports, require, module, __filename, __dirname) {
// your module
}
You can see this wrapper by executing the following snippet in your command-line:
1
node -e "console.log(require('module').wrapper)"
These are variables injected into your module and are available as “global” ones, even though they are not really global. I highly recommend that you look into them, especially into the module variable. You can just call console.log(module) in a javascript file. Try to compare results when you print from a “main” file, and then from a required one.
Next, let’s look into the exports object – we will have a small example showing some caveats related to it:
1
2
3
4
5
exports.name = 'our name'; // this works
exports = { name: 'our name' }; // this doesn't work
module.exports = { name: 'our name' }; // this works!
The example above might puzzle you. Why is it so? The answer is in the nature of the exports object – it is just an argument passed to a function, so in the case that we assign a new object to it, we just rewrite this variable, and the old reference is gone. It is not fully gone, though – module.exports is the same object - so they are actually the same reference to a single object:
1
module.exports === exports; // true
The last part is require – it is a function which takes a module name and returns the exports object of this module. How exactly, does it resolve a module? There is a pretty straightforward rule:
- check core modules with provided name
- if path begins with
./or../, try to resolve a file - if there was no file found, try to find a directory with
index.jsfile in it - if path does not begin with
./or../, go to thenode_modules/and check folder/file there:- in the folder where we run script
- one level above, until we reach
/node_modules
There are also some other places, which are mostly for compatibility, and you can also provide your path to look in by specifying the variable NODE_PATH, which might be useful. If you want to see the exact order in which node_modules are being resolved, just print the module object in your script and look for the paths property. For me, it prints the following:
1
2
3
4
5
6
7
8
9
10
11
12
13
➜ tmp node test.js
Module {
id: '.',
exports: {},
parent: null,
filename: '/Users/seva.zaikov/tmp/test.js',
loaded: false,
children: [],
paths:
[ '/Users/seva.zaikov/tmp/node_modules',
'/Users/seva.zaikov/node_modules',
'/Users/node_modules',
'/node_modules' ] }
Another interesting thing about require is that after the first require call module is cached, and won’t be executed again, we’ll just get back the cached exports object – so it means that you can do some logic and be sure that it will be executed only once after the first require call (this is not exactly true – you can remove then module id from require.cache, and then the module might be reloaded, if it is required again).
Environment Variables
As it is stated in the twelve-factor app, it is a good practice to store configuration in environment variables. You can set up variables for the shell session:
1
export MY_VARIABLE="some variable value"
Node is a cross-platform engine, and ideally your application should be possible to run on any platform (e.g. for development. You choose the production environment to run your code, and usually it is some Linux distributive). My examples cover only MacOS/Linux, and won’t work for Windows. The syntax of environment variables in Windows is different, you can use something like cross-env, but you should keep it in mind in other cases as well.
You can add this line to your bash/zsh profile so it is set up in any new terminal session. However, you usually just run your application providing these variables specifically for this instance:
1
APP_DB_URI="....." SECRET_KEY="secret key value" node server.js
You can access these variables in your Node.js app using the process.env object:
1
2
3
4
const CONFIG = {
db: process.env.APP_DB_URI,
secret: process.env.SECRET_KEY
}
Putting Everything Together
In this example we will create a simple http server, which will return a file named as a provided url string after /. In case the file does not exist, we will return the 404 Not Found error, and in case the user tries to cheat and use a relative or nested path, we will send him a 403 error.
We used some of these functions before, but did not really document them – this time it will be a heavily-documented code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
// we require only built-in modules, so Node.js
// does not traverse our `node_modules` folders
// https://nodejs.org/api/http.html#http_http_createserver_options_requestlistener
const { createServer } = require("http");
const fs = require("fs");
const url = require("url");
const path = require("path");
// we pass the folder name with files as an environment variable
// so we can use a different folder locally
const FOLDER_NAME = process.env.FOLDER_NAME;
const PORT = process.env.PORT || 8080;
const server = createServer((req, res) => {
// req.url contains full url, with querystring
// we ignored it before, but here we want to ensure
// that we only get pathname, without querystring
// https://nodejs.org/api/http.html#http_message_url
const parsedURL = url.parse(req.url);
// we don't need the first `/` symbol
const pathname = parsedURL.pathname.slice(1);
// in order to return a response, we have to call `res.end()`
// https://nodejs.org/api/http.html#http_response_end_data_encoding_callback
//
// > The method, response.end(), MUST be called on each response.
// if we don't call it, the connection won't close and a requester
// will wait for it until the timeout
//
// by default, we return a response with [code 200](https://en.wikipedia.org/wiki/List_of_HTTP_status_codes)
// in case something went wrong, we are supposed to return
// a correct status code, using the `res.statusCode = ...` property:
// https://nodejs.org/api/http.html#http_response_statuscode
if (pathname.startsWith(".")) {
res.statusCode = 403;
res.end("Relative paths are not allowed");
} else if (pathname.includes("/")) {
res.statusCode = 403;
res.end("Nested paths are not allowed");
} else {
// https://nodejs.org/en/docs/guides/working-with-different-filesystems/
// in order to stay cross-platform, we can't just create a path on our own
// we have to use the platform-specific separator as a delimiter
// path.join() does exactly that for us:
// https://nodejs.org/api/path.html#path_path_join_paths
const filePath = path.join(__dirname, FOLDER_NAME, pathname);
const fileStream = fs.createReadStream(filePath);
fileStream.pipe(res);
fileStream.on("error", e => {
// we handle only non-existant files, but there are plenty
// of possible error codes. you can get all common codes from the docs:
// https://nodejs.org/api/errors.html#errors_common_system_errors
if (e.code === "ENOENT") {
res.statusCode = 404;
res.end("This file does not exist.");
} else {
res.statusCode = 500;
res.end("Internal server error");
}
});
}
});
server.listen(PORT, () => {
console.log(`application is listening at the port ${PORT}`);
});
Conclusion
In this guide we covered a lot of fundamental Node.js principles. We did not dive into specific APIs, and we definitely missed some parts, but this guide should be a good starting point to feel confident while reading API, and editing existing or creating new scripts. You are now able to understand errors, what interfaces built-in modules use, and what to expect from typical Node.js objects and interfaces.
Next time, we’ll cover web servers using Node.js in depth, Node.js REPL, how to write a CLI application, and how to use Node.js for small scripts. You can subscribe to get notifications about these new articles.